
текст
Google разработала новую технологию повышения качества изображений
Она позволяет увеличить разрешение до 16 раз без потери качества.
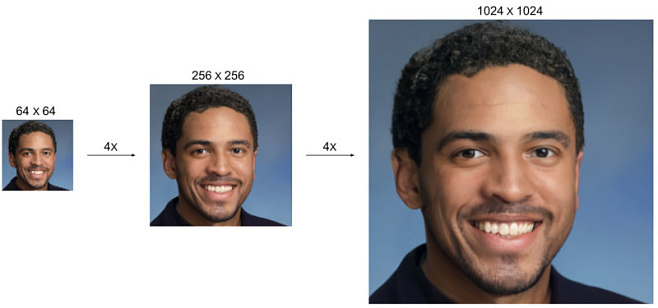
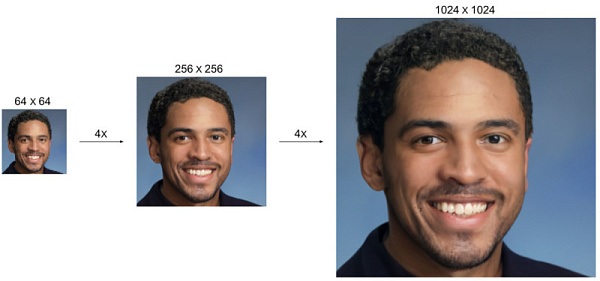
Специалисты внутренней команды Google Brain Team разработали два связанных алгоритма на базе диффузных моделей, которые позволяют увеличивать разрешение изображений до 16 раз без потери качества. Об этом стало известно из пресс-релиза, который исследователи опубликовали в блоге Google AI.
Первым алгоритмом в технологии стало увеличение разрешения посредством повторного уточнения, или SR3. Чтобы повысить качество картинки, нейросеть увеличивает её, добавляя шум, а затем постепенно убирает его. Отмечается, что для этого алгоритм обучается методам искажения изображений.
По оценке Brain Team, по результатам работы SR3 превосходит качество существующих сегодня генеративных алгоритмов, таких как PULSE и FSRGAN. Особенно разница в эффективности проявляется при сопоставлении увеличенных с помощью старого и нового подхода к ИИ портретов и пейзажей.
Другим алгоритмом Google стала диффузионная модель CDM, которую специалисты обучили на миллионах изображений высокого разрешения из базы ImageNet. Разработка использует каскадный подход и может увеличивать изображения в два этапа, в восемь или 16 раз, с разрешения 64x64 до 256x256 или 1024x1024.
Фото: Google AI Blog
Технологии
Илья Склюев
Машины и Механизмы
Всего 0 комментариев

 SpaceX отправила на МКС муравьёв, авокадо и робота
SpaceX отправила на МКС муравьёв, авокадо и робота Марсоход Perseverance добыл первый образец планетарного грунта
Марсоход Perseverance добыл первый образец планетарного грунта







