
Ученые из МФТИ оценили способности ChatGPT определять тип личности автора текстов


Все большую актуальность в мире приобрели различные психологические тесты, позволяющие выявить личностные характеристики. Ими пользуются, к примеру, в крупных компаниях при найме сотрудников для предотвращения угроз, связанных с человеческим фактором. Во многих ситуациях подобное тестирование необходимо проводить незаметно. Здесь на помощь приходят тексты, в которых так или иначе отразилась личность автора. Это могут быть сообщения в соцсетях, электронные письма, документы, эссе. Почему бы их анализ не поручить большим языковым моделям?
Мария Молчанова и Дарья Ольшевская, исследовательницы из лаборатории нейронных систем и глубокого обучения МФТИ, задались вопросом, может ли ChatGPT решить задачу классификации черт личности лучше, чем традиционные тесты. Их также интересовал ход рассуждения модели и что на него влияет.
Исследователи опирались на две модели личности: «Большую пятерку» и типологию Майерс—Бриггса. Для анализа взяли три размеченных датасета с текстами — Essays, PersonalityCafe и Twitter, из которых для тестирования выбрали по 150 фрагментов. На их примере ChatGPT предстояло отделить экстравертов от интровертов.
При формулировке запросов к модели ученые использовали различные методы конструирования промптов — инструкций. Каждый запрос снабжали двумя промптами — системным и пользовательским. Системная часть включала в себя инструкцию для проведения теста, пользовательская — фрагмент текста. Методы конструирования промптов отличались логикой, по которой модель должна строить рассуждения. Модель должна была объяснить свой ответ, предоставив текст рассуждений, который в дальнейшем был отдельно проанализирован.
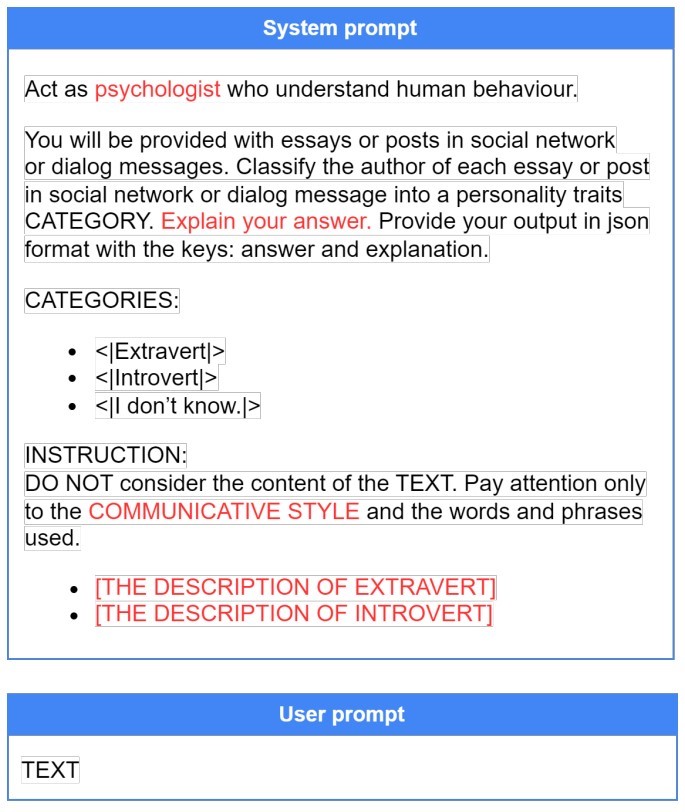 Пример
одного из запросов в формате «обучение по контексту» (In-Context Learning,
ICL). Системная часть начинается словами: «Действуй как психолог, который
понимает поведение человека. Тебе дадут текст, сообщения из соцсетей или диалог
с форума. Классифицируй автора каждого текста по категориям черт личности.
Объясни свой ответ». Далее следует список категорий и подробная инструкция,
включая формат вывода. Источник: 2024 2nd International Conference on Foundation and
Large Language Models (FLLM)
Пример
одного из запросов в формате «обучение по контексту» (In-Context Learning,
ICL). Системная часть начинается словами: «Действуй как психолог, который
понимает поведение человека. Тебе дадут текст, сообщения из соцсетей или диалог
с форума. Классифицируй автора каждого текста по категориям черт личности.
Объясни свой ответ». Далее следует список категорий и подробная инструкция,
включая формат вывода. Источник: 2024 2nd International Conference on Foundation and
Large Language Models (FLLM)Каждый фрагмент текста прошел два цикла тестирования, что позволило сравнить ответы между собой. Ответы оценивали по степени достоверности, точности и полноты. Также анализировали ответы, в правильности которых модель не была уверена.
Лучшие результаты модель показала при анализе текстов из датасета, составленного на основе текстов с форума PersonalityCafe, в сочетании с запросами в формате «обучение по контексту» и «подсказка и рассуждение» (Clue And Reasoning Prompting). Причем последний подход стимулировал модель давать более развернутые ответы с большим числом выявленных черт, что потенциально можно использовать на практике. Тестирование фрагментов из Essays не принесло качественных результатов, а ответы модели при обращении к датасету Twitter оказались неудовлетворительными. Как отметили авторы, отличие в качестве определения черт может быть связано с рядом параметров, например, разной длиной текстов, тематикой, форматом — эссе, сообщения из соцсетей и т. д.
«Большая языковая модель в нашем эксперименте немного отстает от стандартных подходов, но у нее есть ряд плюсов. Работа с ней дает простор для новых задач. В отличие от традиционных подходов, модель может думать логически и объяснять, почему приняла то или иное решение. Также большие языковые модели дают возможность гибкой настройки инструкций, в которых исследователи могут задавать методы, с помощью которых модель может осуществлять классификацию», — рассказала исследовательница лаборатории нейронных систем и глубокого обучения МФТИ Мария Молчанова, первый автор статьи.
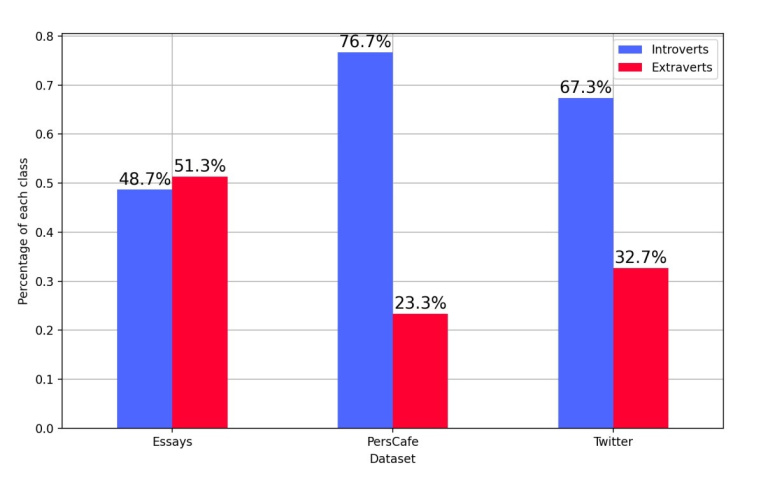 Распределение
интровертов и экстравертов в трех датасетах. Источник: 2024 2nd International Conference on Foundation and
Large Language Models (FLLM)
Распределение
интровертов и экстравертов в трех датасетах. Источник: 2024 2nd International Conference on Foundation and
Large Language Models (FLLM)
Использование большой языковой модели позволяет автоматизировать не только процесс тестирования, но и анализ ответов. В последнем случае выяснилось, что при разных подходах к созданию запроса модель генерирует разные ответы разной длины и детализации.
«Мы создали инструмент, который позволяет расширить список черт личностей, а не только выявлять экстравертов и интровертов, а также помогает исследователям ставить эксперименты с разработкой инструкций для данной задачи. Это открывает новые возможности для анализа», — подчеркнула исследовательница.
По словам авторов, работа с большими языковыми моделями для психологического тестирования предлагает совершенно новый подход по сравнению с традиционными методами.
Статья опубликована в трудах 2024 2nd International Conference on Foundation and Large Language Models (FLLM),Dubai, United Arab Emirates.
Технологии
МФТИ

 Физики разработали новый метод для улучшения свойств тонких пленок квантовых точек
Физики разработали новый метод для улучшения свойств тонких пленок квантовых точек Создан новый класс гибридных люминофоров
Создан новый класс гибридных люминофоров







