

текст
Машинное лицемерие
Просмотр записей с камер наблюдения в поисках «засветившегося» преступника – стандартная сцена из детективного фильма. Идеальная кинематографическая версия: детектив запускает программу, нажимает пару кнопок и идет варить кофе. Компьютер тем временем победоносно пищит, и следующим кадром мы видим полицейские сирены.
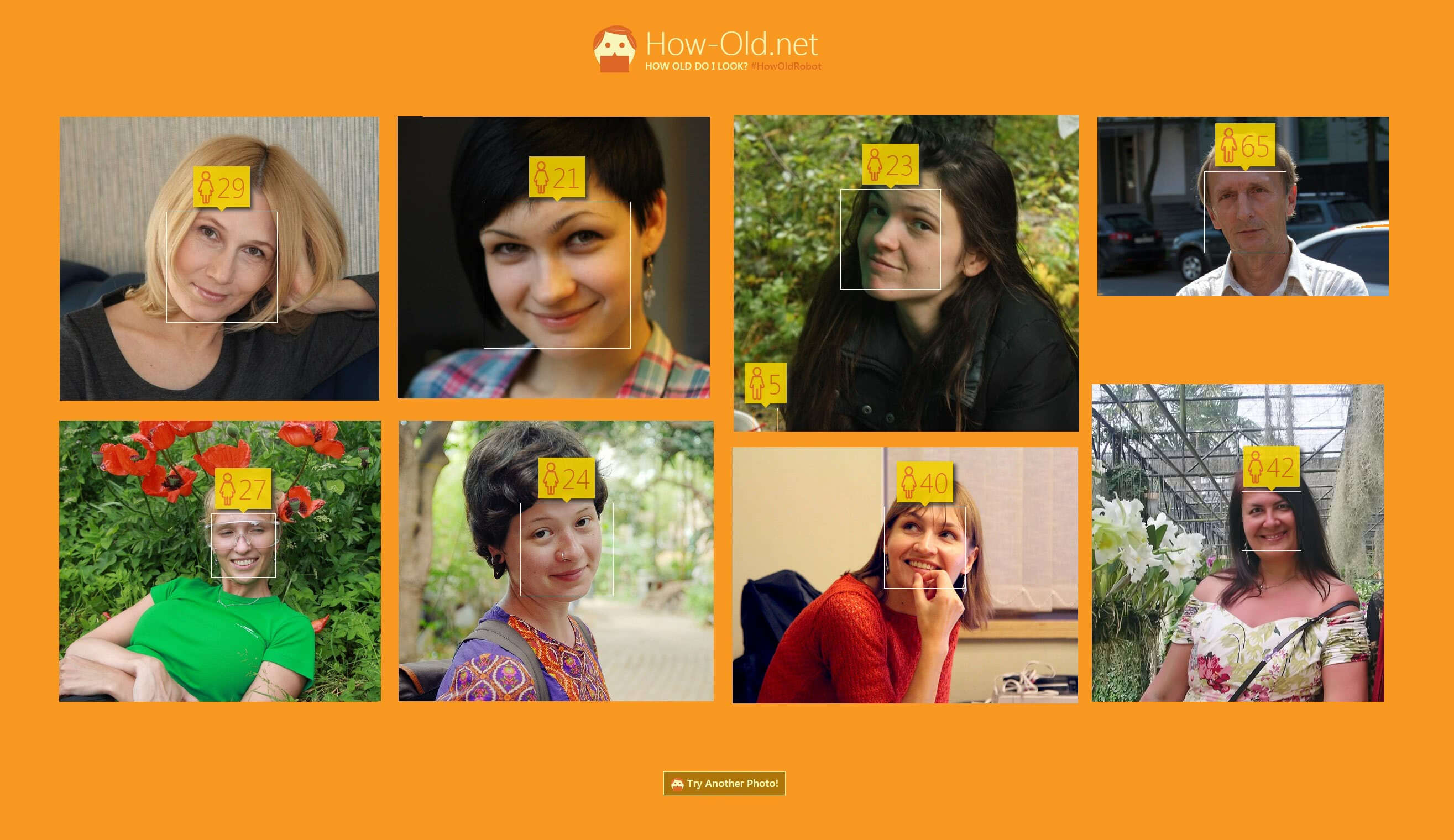
Распознавание лиц прочно закрепилось в цифровом мире в развлекательных целях. Facebook активно использует этот механизм при загрузке фотографий: рамка вокруг лица появляется автоматически, вам лишь надо указать ссылку на друга. В этой же категории – недавно запущенный проект Microsoft how-old.net, пытающийся определить пол и возраст человека на фото. Точность срабатывания далека от идеала, и в зависимости от угла поворота и освещения 25-летний юноша вполне может оказаться 34-летней мадемуазель. Еще распознавание лиц можно встретить на многих ноутбуках и компьютерах, где оно используется для аутентификации пользователя. Со всем этим можно побаловаться прямо сейчас. Но есть куда более серьезные вещи, где ошибки будут вызывать уже не улыбки, а головную боль.
Пример неудачного опыта – автоматизация пропускного контроля. Подобные системы уже снимали со службы в полиции Лондона, Флориды и аэропорту Бостона. Все они тестировались в начале 2000-х годов, и во всех случаях, помимо установки дорогостоящего оборудования, для работы требовалось постоянное участие оператора, то есть об абсолютной автоматизации речи не шло. Технические средства тех лет не позволяли достигнуть точности срабатывания больше 60 %.
Другим серьезным применением является анализ уже свершившихся происшествий. Именно тут конкурируют человек и машина, пытаясь в самые короткие сроки получить результат, причем стоимость ошибки в этом случае возрастает многократно. После теракта во время Бостонского марафона подозреваемых на фотографиях и видео искали обычные люди, компьютеры по ним не отработали. Аналогично во время беспорядков в Англии в социальные сети выгружались сотни фотографий правонарушителей, а пользователи уже сами опознавали их и сообщали полиции.
Детектирование лица и сопоставление его с теми, что есть в базе данных, в режиме реального времени с потокового видео – куда более интересная и сложная проблема. Именно такую систему планируют установить в Петербурге на стадионе «Зенит Арена» к 21 чемпионату мира по футболу. Сейчас она в тестовом режиме работает на стадионе «Петровский». Согласно задумке, она должна опознать нарушителя порядка, занесенного в черный список, еще перед турникетами.
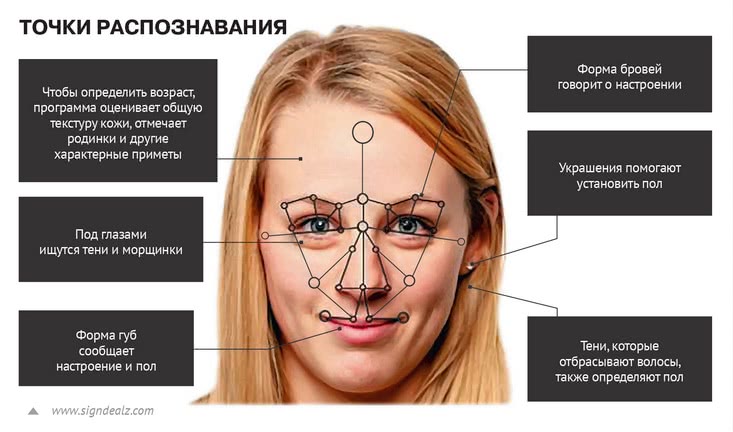
Итак, задача: найти в кадре лицо и определить, совпадает ли оно с теми, что хранятся в базе данных. Тут надо учитывать особенности машинного зрения. В отличие от человека, воспринимающего картинку сначала целиком, а потом по частям, компьютер сразу начинает с частей. Машина не «дорисовывает» плоское изображение до трехмерного объекта, как это делает наш мозг. И все алгоритмы распознавания лиц в итоге работают с пикселями, наименьшей дискретной величиной цифрового изображения. Считается, что минимальное расстояние между глазами должно составлять 90 пикселей. В противном случае распознать лицо вряд ли удастся. Но разрешение – не единственный критерий. Другими важными составляющими являются угол поворота лица и освещение. Пока эталон для алгоритмов распознавания – идеальный анфас. Если отклониться от него на 20 или 30 градусов, то результат может выйти нулевым, машина даже не поймет, что это человек. Если половина лица сильно засвечена или, наоборот, затемнена, детектировать его тоже не удастся. Ну и никто еще не запрещал носить очки, кепки, капюшоны или делать раскраску лица в стиле футбольных фанатов.
Откуда столько ограничений? Детектирование лица – достаточно сложный процесс. Возьмем два распространенных алгоритма, принципиально отличающихся друг от друга: метод Виолы-Джонса и локальные бинарные шаблоны. Первый метод предложен в 2001 году Полом Виолой (Paul Viola) и Майклом Джонсом (Michael Jones). Он работает по принципу сканирующего окна – изображение обрабатывается несколько раз с разным размером этого окна. Допустим, на начальном этапе – 30 на 30 пикселей. Окно двигается по изображению, вычисляя расположение различных признаков. За каждый шаг вычисляется около 200 000 признаков. В методе Виолы-Джонса используются так называемые признаки Хаара. Они представляют собой разность сумм пикселей двух смежных регионов областей. Например, для лиц характерно, что область глаз темнее, чем область щек. Следовательно, общим признаком Хаара для лиц являются 2 смежных прямоугольных региона, лежащих на глазах и щеках.
Иначе работает метод локальных бинарных шаблонов. Фактически, это простой оператор, позволяющий проанализировать текстуру изображения. Например, выбирается некоторый опорный пиксель и окрестность из восьми, прилегающих к нему. После этого начинается обход этих соседних пикселей по часовой стрелке, и если интенсивность рассматриваемого пикселя больше или равна центральному, ему приписывается значение «1», в противном случае «0». Благодаря такому обходу создается восьмиразрядный бинарный код, описывающий окрестности пикселя. Из этих данных можно понять, что находится на участке: 00000000 – это пятно с фоном, 11111111 – просто пятно, 11111000 – конец линии.

После удачного захвата лица его изображение нужно выровнять. Сгладить геометрические сдвиги и приблизить к идеальному анфасу, исправить, где возможно, недочеты в яркости. Только после этого можно приступать к распознаванию. Для компьютера это значит – вычислить некоторые признаки и сравнить с теми, что есть в базе, чтобы найти соответствие. Для этого тоже есть свои методы. Например, в случае применения активной модели внешнего вида (Active Appearance Models, AAM) будут вычислены два параметра: параметр формы и параметр внешнего вида, связанный с моделью пикселей или текстурой. На лице выбираются опорные точки, описывающие геометрию лица: расстояние между уголками губ, глазами, зрачками, длина бровей и прочее. Имея достаточно большой набор признаков, можно идентифицировать по ним людей.
Еще одним методом является метод гибкого сравнения на графах. Граф – математическое понятие. Визуально его можно представить как множество вершин (узлов), соединенных ребрами. Суть метода сводится к сопоставлению графов, описывающих изображения лиц. В системах распознавания графы могут представлять собой как структуру, образованную характерными точками лица, так и прямоугольную решетку. В любом случае каждое ребро графа взвешено – то есть ему присвоено числовое значение, означающее расстояние между смежными вершинами. На этапе распознавания один из графов, эталонный, представляющий искомое лицо анфас, остается неизменным. А другой, полученный с изображения в произвольном ракурсе, деформируется для подгонки к первому. Если степень деформации слишком высока – лицо не то.
Представляете, какой мощностью и точностью должна обладать система, чтобы на том же стадионе «Петровском» поддерживать достаточную пропускную способность, не вызывающую у зрителей потока ненормативной лексики? И ведь эту систему надо обучать на множестве лиц вручную, от этого будет зависеть ее эффективность. Некоторые системы необходимо переучивать заново после каждого нового добавления изображения. Но и это не страхует от ложного срабатывания и пропуска действительного совпадения.
Конечно, со временем качество видеоаппаратуры, мощность компьютеров позволяют применять новые подходы к распознаванию лиц. Например, интересными решениями обладает отечественная компания VOCORD. Она разработала систему трехмерного моделирования лица из изображений с нескольких камер, расположенных под разными углами. Трехмерная модель имеет понятное преимущество по сравнению с плоской картинкой – отклонения от идеального анфаса меньше влияют на результат работы алгоритма, и, ко всему прочему, можно предпринять попытки по устранению нежелательных объектов, таких как очки, кепка, борода или усы. К сожалению, в открытом доступе нет данных о значениях FAR и FRR, отражающих число ошибок системы, поэтому остается только верить на слово разработчикам. Они утверждают, что точность – 100 %.

Технологии
Игорь Зубов
Машины и Механизмы
Всего 0 комментариев

 Галактические войны
Галактические войны В небо из-под воды
В небо из-под воды  Алюминиевый «поролон»
Алюминиевый «поролон» И снова «Здравствуйте!»
И снова «Здравствуйте!» В окопах первой цифровой
В окопах первой цифровой 







